马尔可夫决策过程
构建强化学习问题:马尔可夫决策过程 Markov Decision Processes (MDPs)
MDP组件
马尔可夫决策过程为我们提供了一种形式化顺序决策的方法。 这种形式化是构建通过强化学习解决的问题的基础。
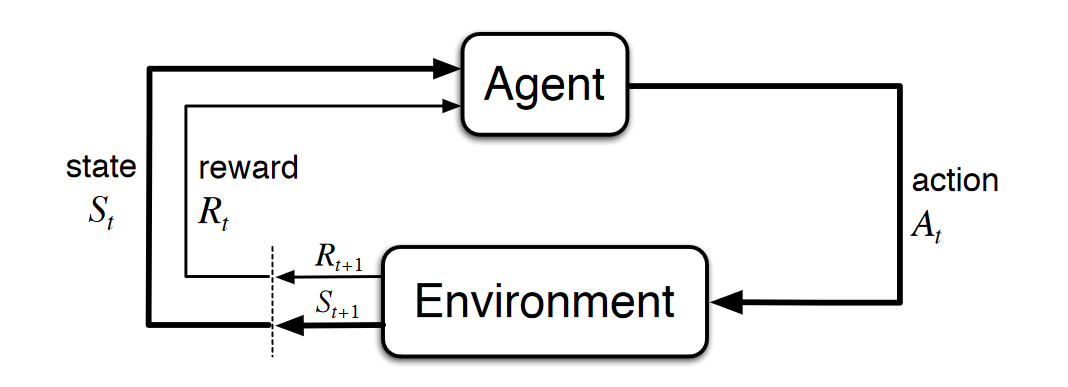
在马尔可夫决策过程中,智能体\(Agent\)与其所在的环境进行交互。这些交互随着时间的流逝依次发生。 在每个时间步\(t\)中,\(Agent\)都会获得环境状态\(s_t\)的编码。给定\(s_t\),\(Agent\)将选择要采取的行动\(a_t\)。 然后,环境通过\(a_t\)将更新新的状态\(s_{t+1}\),并且由于先前的操作,\(Agent\)会获得奖励\(r_{t+1}\)。
一个马尔可夫决策过程的组建包括:
- Agent
- Environment
- State
- Action
- Reward
从给定状态\(State\)中选择动作\(Action\),过渡到新状态并获得奖励\(Reward\)的过程是一遍又一遍地依次进行的,这创建的一系列成为轨迹\(Trajectory\),该轨迹显示状态,动作和奖励的顺序。
在此过程中,\(Agent\)的目标是最大限度地提高在给定这些状态下采取的这些行动所获得的奖励总额。 这意味着\(Agent\)不仅希望最大化即时奖励,还希望最大化其随着时间的推移所获得的累积奖励。
MDP符号表示
在一个马尔可夫决策过程中,有一个状态集合\(S\),动作集合\(A\),奖励集合\(R\),且这些集合的元素是有限的。
-
在每一个时间步\(t = 0, 1, 2, ...\), \(Agent\)接收环境的状态\(S_t \in S\),基于当前状态\(S_t\),\(Agent\)选择一个动作\(A_t \in A\)。形成一个state-action对(\(S_t, A_t\))。
-
时间推移到下一个时间步\(t + 1\),环境受到\(Agent\)选择的动作\(A_t\)影响,将状态从\(S_t\)转为\(S_{t+1} \in S\),此时Agent获得一个数值奖励\(R_{t+1} \in R\),该奖励是关于Agent从状态\(S_t\)选择动作\(A_t\)的奖励。即奖励函数:\(f(S_t, A_t) = R_{t+1}\)
\(Trajectory: S_0, A_0, R_1, S_1, A_1, R_2, S_2, A_2, R_3, ...\)
转换概率
因为集合\(S\)和\(R\)是有限集,随机变量\(S_t\)和\(R_t\)具有明确定义的概率分布,即
期望回报
期望奖励
在一个MDP过程中,是什么驱动强化学习智能体?期望回报 Expected Return
在一个MDP过程中,智能体的目标是最大化它的期望奖励Reward。数学表示方式:
定义在在\(t\)时刻所获得的期望奖励\(G\)是:
\(T\)是最后一个时间步。
期望奖励的概念非常重要,因为这是智能体的目标就是最大化期望奖励。期望奖励是推动智能体做出决策的动力。
折扣期望奖励
在一个MDP过程中,智能体的目标是最大化它的期望折扣奖励Reward
折扣率\(\gamma\),取值0~1之间,是折扣将来奖励的比率。
折扣奖励的定义使智能体更关心即时奖励而不是未来奖励,因为未来奖励将得到更大的折扣。因此,尽管智能体确实考虑了预期在将来获得的奖励,但当智能体做出关于采取特定动作的决定时,越直接的奖励就具有更大的影响力。
策略与值函数
策略
策略:给定一个状态,智能体选择任意一个动作的概率是多少。
策略用符号\(\pi\)表示,\(\pi(a|s)\):在\(t\)时刻,\(\pi\)策略下,给定状态\(s\)选择动作\(a\)的概率是\(\pi(a|s)\)。\(\pi\)是动作\(a\)的概率分布。
Q值函数
Value Functions, which generally give us an idea of how good some given state-action pair is for an agent in terms of expected reward.
值函数:智能体选择某一个状态有多好。从reward的角度看就是,在给定一个状态选择一个动作可能增加或者减少reward。
动作值函数:\(q_\pi\)表示基于策略\(\pi\)的动作值函数。即在给定一个状态,基于策略\(\pi\)选择一个动作后,给定的值,这个值用来评价选择该动作有多好。值用期望奖励定义
\(q_\pi\)称Q值函数,Q: quality
最优策略
什么是最优策略?
对于所有状态\(s\),当且仅当基于策略\(\pi\)的值函数均大于其他所有策略\(\pi^\prime\)的值函数时,这个策略\(\pi\)就是最优测策略。
最优Q值函数
相似的,最优策略有一个最优动作值函数,即最优Q值函数,\(q_*\)表示。
\(q_*\)表示对于给定状态动作对,该策略比任何其他策略更能获得最大期望奖励。
贝尔曼最优方程
\(q_*\)最优Q值函数的基本属性,满足贝尔曼最优方程: