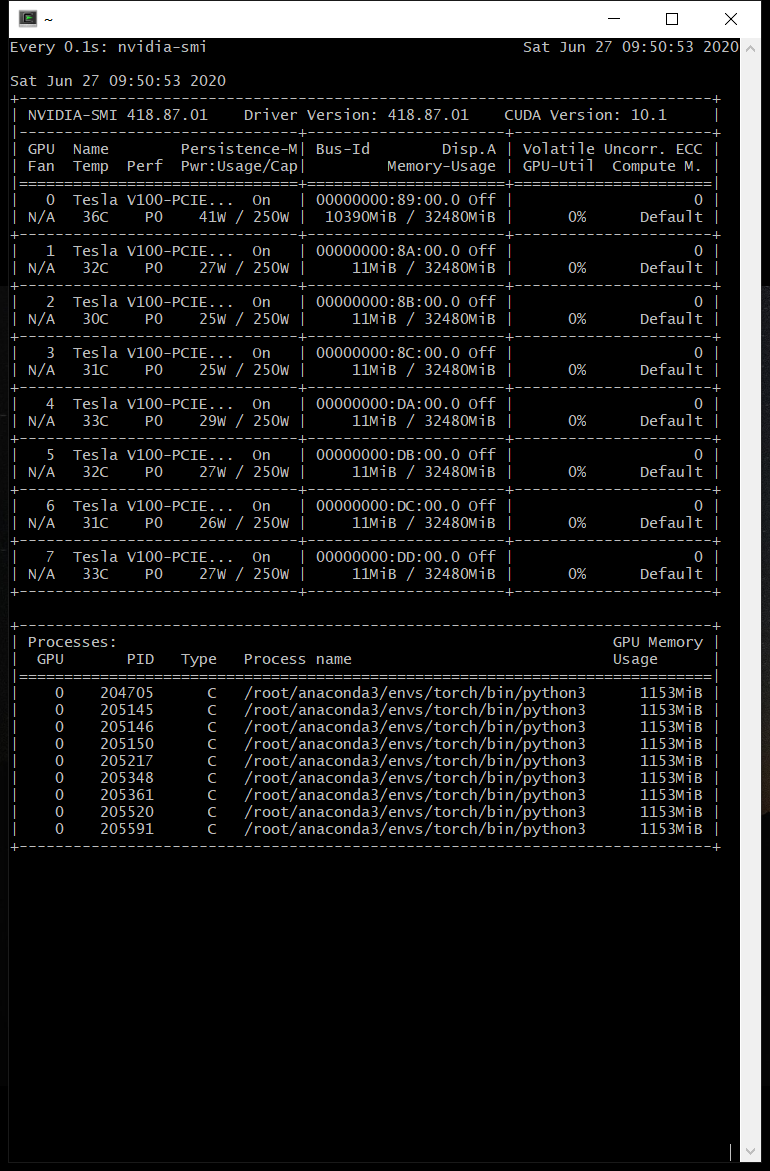
主卡线程暴涨
异常:
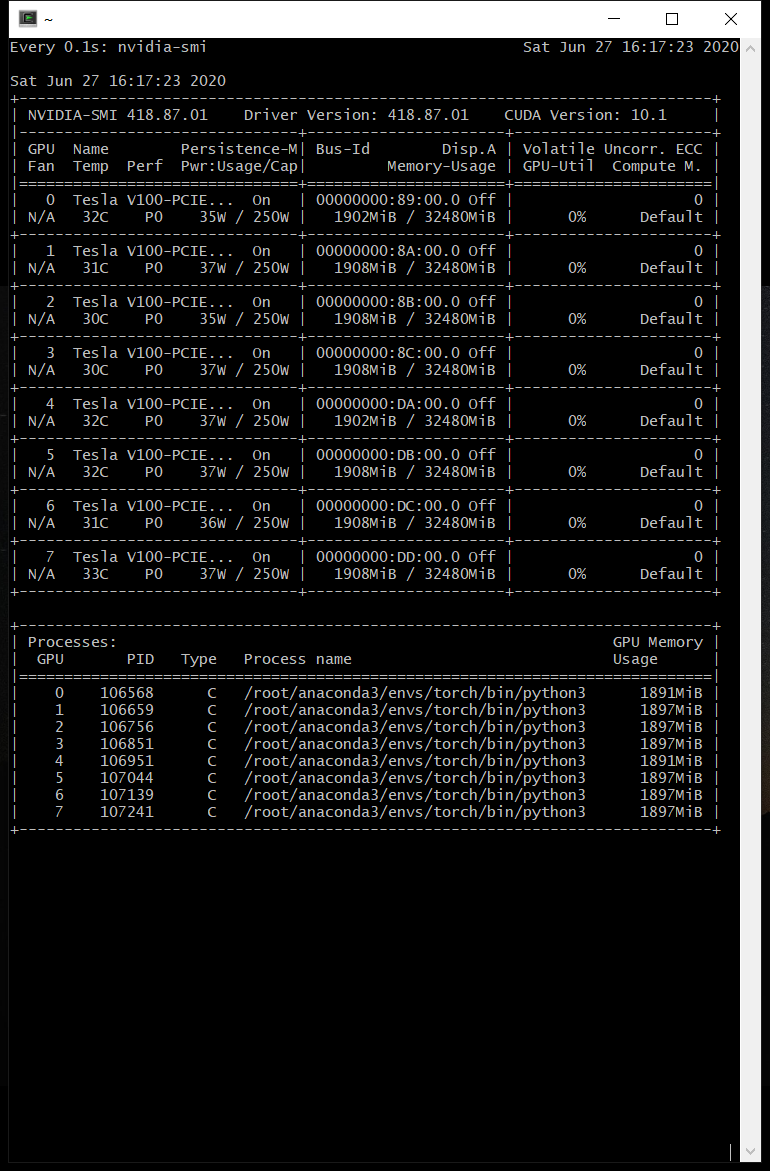
正常:
def to_var(x, on_cpu=False, gpu_id=None):
"""Tensor => Variable"""
if torch.cuda.is_available() and not on_cpu:
x = x.cuda(gpu_id, non_blocking=True)
# x = Variable(x)
return x
def normal_kl_div(mu1, var1,
mu2=to_var(torch.FloatTensor([0.0])),
var2=to_var(torch.FloatTensor([1.0]))):
one = to_var(torch.FloatTensor([1.0]))
return torch.sum(0.5 * (torch.log(var2) - torch.log(var1)
多线程脚本导入时,函数参数总是执行to_var()。当线程num_workers越多,数据无效装入cuda就越多。
修改
def normal_kl_div(mu1, var1, mu2, var2):
mu2=to_var(torch.FloatTensor([0.0]))
var2=to_var(torch.FloatTensor([1.0]))
one = to_var(torch.FloatTensor([1.0]))
return torch.sum(0.5 * (torch.log(var2) - torch.log(var1)
共享内存问题
Training Start!
0%| | 0/40937 [00:00<?, ?it/s]
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
Traceback (most recent call last):
File "/root/anaconda3/envs/torch/lib/python3.7/multiprocessing/queues.py", line 236, in _feed
obj = _ForkingPickler.dumps(obj)
File "/root/anaconda3/envs/torch/lib/python3.7/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
fd, size = storage._share_fd_()
RuntimeError: unable to write to file </torch_3531_3962650647>
RuntimeError: DataLoader worker (pid 3527) is killed by signal: Bus error.
Please note that PyTorch uses shared memory to share data between processes, so if torch multiprocessing
is used (e.g. for multithreaded data loaders) the default shared memory segment size that container runs with
is not enough, and you should increase shared memory size either with --ipc=host or --shm-size command line
options to nvidia-docker run.
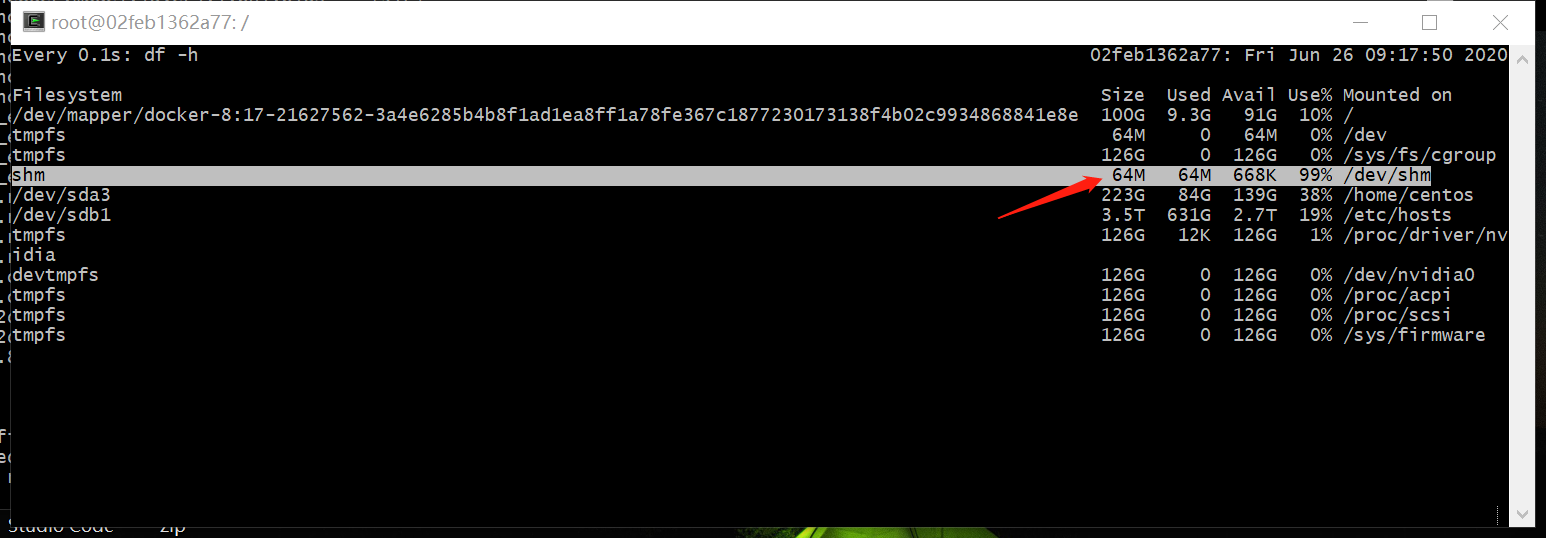
多进程数据加载Dataloader,Docker容器的共享内存/dev/shm不足
- 修改当前Docker的shm-size。挂载点/dev/shm
- docker ps -a
- docker inspect [container id] | grep Id
- systemctl stop docker
- cd [container directory]
- 修改hostconfig.json和config.v2.json
- systemctl start docker
- docker start [container id]
- num_workers设置0
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=16,
shuffle=True,
num_workers=0,
pin_memory=True,
collate_fn=dataset.collate_fn
)
lamda对象不能序列化问题
-- Process 0 terminated with the following error:
Traceback (most recent call last):
File "/root/anaconda3/envs/torch/lib/python3.7/site-packages/torch/multiprocessing/spawn.py", line 19, in _wrap
fn(i, *args)
File "/home/yckj2939/project/yckj_project/mhred/pytorch/train.py", line 107, in main_worker
model.train(train_sampler, train_data_loader, eval_data_loader)
File "/home/yckj2939/project/yckj_project/mhred/pytorch/utils/time_track.py", line 18, in timed
result = method(*args, **kwargs)
File "/home/yckj2939/project/yckj_project/mhred/pytorch/solver.py", line 160, in train
for batch_i, (conversations, conversation_length, sentence_length, images, images_length) in enumerate(tqdm(train_data_loader, ncols=80)):
File "/root/anaconda3/envs/torch/lib/python3.7/site-packages/tqdm/_tqdm.py", line 979, in __iter__
for obj in iterable:
File "/root/anaconda3/envs/torch/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 278, in __iter__
return _MultiProcessingDataLoaderIter(self)
File "/root/anaconda3/envs/torch/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 682, in __init__
w.start()
File "/root/anaconda3/envs/torch/lib/python3.7/multiprocessing/process.py", line 112, in start
self._popen = self._Popen(self)
File "/root/anaconda3/envs/torch/lib/python3.7/multiprocessing/context.py", line 223, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "/root/anaconda3/envs/torch/lib/python3.7/multiprocessing/context.py", line 284, in _Popen
return Popen(process_obj)
File "/root/anaconda3/envs/torch/lib/python3.7/multiprocessing/popen_spawn_posix.py", line 32, in __init__
super().__init__(process_obj)
File "/root/anaconda3/envs/torch/lib/python3.7/multiprocessing/popen_fork.py", line 20, in __init__
self._launch(process_obj)
File "/root/anaconda3/envs/torch/lib/python3.7/multiprocessing/popen_spawn_posix.py", line 47, in _launch
reduction.dump(process_obj, fp)
File "/root/anaconda3/envs/torch/lib/python3.7/multiprocessing/reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj)
AttributeError: Can't pickle local object 'Vocab.load.<locals>.<lambda>'
def load(self, word2id_path=None, id2word_path=None):
if word2id_path:
with open(word2id_path, 'rb') as f:
word2id = pickle.load(f)
# Can't pickle lambda function
self.word2id = defaultdict(lambda: UNK_ID)
self.word2id.update(word2id)
self.vocab_size = len(self.word2id)
pickle模块不能序列化lambda,需要自定义函数
from collections import defaultdict
UNK = 1
dic = defaultdict(lambda: UNK)
print(dic['Jerry']) # res: 1 ---> UNK
##################################################
class Test:
def default_unk(self):
return UNK
def update(self):
self.w2i = defaultdict(self.default_unk)
return self.w2i
test = Test()
dic = test.update()
print(dic['Annie']) # res: 1 ---> UNK
luly.lamost.org/blog/python_multiprocessing
加载分布式模型到单卡
RuntimeError: Error(s) in loading state_dict for MHRED:
Missing key(s) in state_dict: "encoder.embedding.weight", ...
Unexpected key(s) in state_dict: "module.encoder.embedding.weight", ...
Distributed包装的模型在保存时,权值参数前面会带有module字符,然而自己在单卡环境下,没有用Distributed包装的模型权值参数不带module。
方案一:保存模型时把module去掉
if len(gpu_ids) > 1:
t.save(net.module.state_dict(), "model.pth")
else:
t.save(net.state_dict(), "model.pth")
方案二: 创建新的模型OrderedDict不包含module
loc = 'cuda:{}'.format(self.config.gpu)
checkpoint = torch.load(checkpoint_path, map_location=loc)
checkpoint_new = OrderedDict()
for key, value in checkpoint.items():
key = key[7:] # remove `module.`
checkpoint_new[key] = value
self.model.load_state_dict(checkpoint_new)
when loading the module, you need to provide an appropriate map_location argument to prevent a process to step into others’ devices. If map_location is missing, torch.load will first load the module to CPU and then copy each parameter to where it was saved, which would result in all processes on the same machine using the same set of devices
https://pytorch.org/tutorials/intermediate/ddp_tutorial.html#save-and-load-checkpoints